Update 7
Update 7
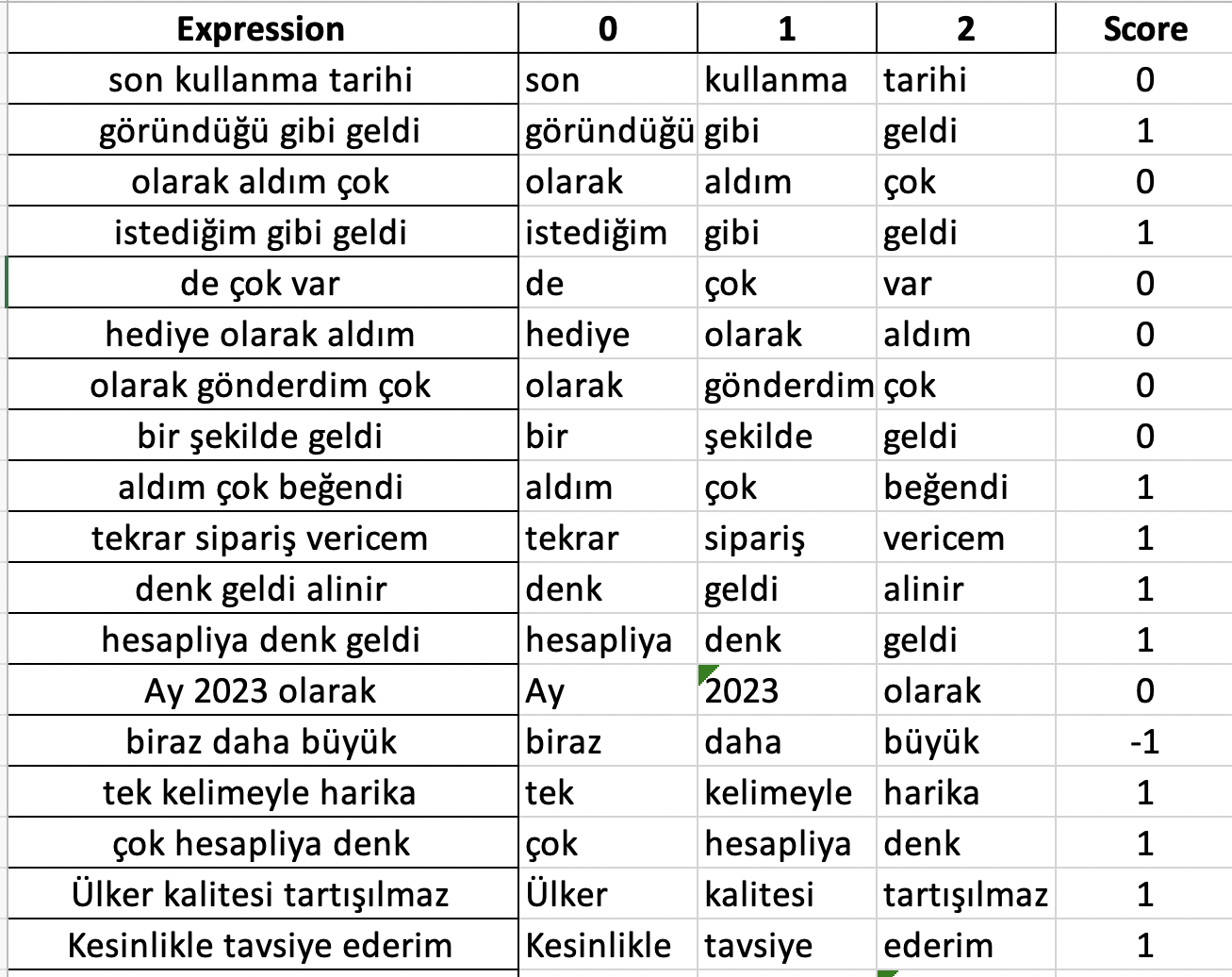
This week I worked on assigning scores to the most common expressions I obtained from my unigram, bigram, and trigram models. Because I couldn’t find any pre-existing models on Turkish colloquial language, I assigned scores individually to each expression. This will definitely be a constraint when I am doing the analysis and the calculation of scores for each comment left on the products.
The way I assigned scores was:
- “+1” for positive expressions
- “0” for neutral expressions
- “-1” for negative expressions
Another challenge I faced surrounding the assignment of sentiment scores to expressions were that some expressions were usually too short to produce sentiment. I could derive the sentiment from seeing the group of words used together, however if the start of the bigram is a negation word than it would alter the whole meaning of the expression and score. Hence, this analysis will only provide a preliminary insight into how sentiment scores change depending on the seller.
Furthermore, as I was assigning the scores to the expression, I realized that the ungiram scores tended to be more neutral compared to the bigram and trigram scores. Likewise, the trigram scores were more variable in terms of positivity and negativity compared to bigram scores. So as we increase the number of words in the n-grams it yields a better understanding of the sentiment of the expressions.
As for the analysis of the sentiment scores in comments. I am now implementing an algorithm that searches for each expression in the comment. If the search returns true, then the score of that expression will be added to the sentiments overall score. Unfortunately, I don’t think this will be the most efficient algorithm to calculate the sentence-based scores. So, I will be researching for better ways to do this.
Here I will include a screenshot of the trigram sentiment scores in the Excel file: